第2回 基板設計と機械学習アルゴリズムのいろいろ

AIを構成する要素として、機械学習があることを前回説明しました。機械学習と一口に言ってもさまざまなアルゴリズムがあり、初学者にとっては、どれを使ったらよいかわかりません。本稿では、機械学習を分類し、どのようアルゴリズムを使ったよいか解説します。
■機械学習のいろいろ
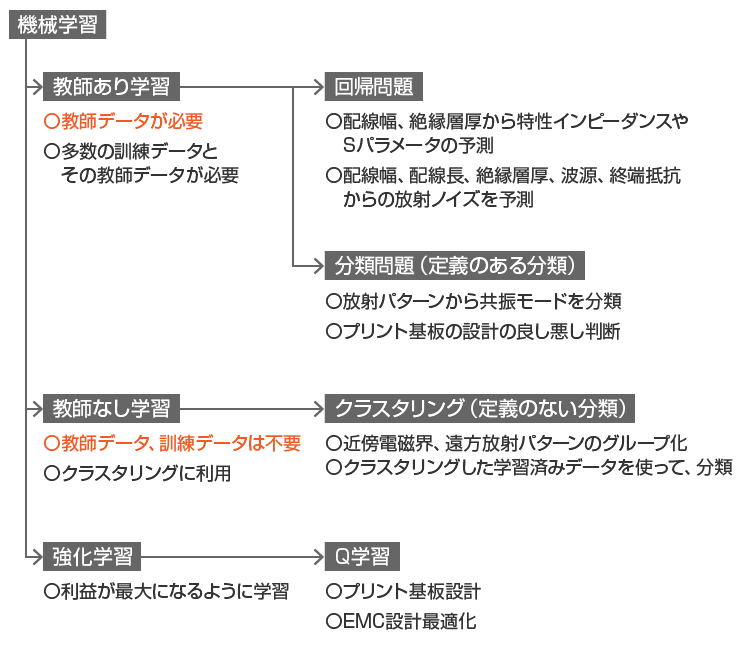
図1 機械学習の分類
図1 に示すように、機械学習は「教師あり学習」「教師なし学習」「強化学習」の3つに分けることができます。
■教師あり学習
教師あり学習とは、機械を訓練するための教師データがある学習(訓練)です。訓練用の入力データに対して正しい出力データ(ラベル)が付与されます。
教師あり学習には、次の2つあります。
- データからデータを予測する回帰問題
- データが定義されたグループに分類する分類問題
「回帰問題」は、データの入力に対して連続的なデータを出力します。一方、「分類問題」では、データを教師データのラベルに従い分類します。実は、分類するグループを連続的にしたものが回帰になりますので、回帰問題に使えるアルゴリズムは、分類問題に利用できます。回帰問題、分類問題の具体例を以下に示します。
● 回帰問題
回帰問題は、数値データから数値データを予測します。例えば、配線幅、絶縁層厚から特性インピーダンス($Z_0$)や$S$パラメータの予測、近傍磁界、遠方放射電界の予測が可能です。
$Z_0$や$S$パラメータの予測であれば、配線情報(配線幅、絶縁層厚、比誘電率、配線長)と$Z_0$、$S$パラメータを一組のデータ・セットとして複数(数百~数千個)のデータを準備して機械(コンピュータ)を訓練します。近傍磁界や遠方放射電界であれば、プリント基板のレイアウト情報、波源電圧や終端条件と近傍磁界、遠方放射電界のデータ・セットが必要です。$Z_0$や$S$パラメータ、近傍磁界、放射電界は、実測または電磁界シミュレーションで求めることができます。データ・セットの数が最低でも数百個必要な事を考えると、電磁界シミュレーションで求めた方が現実的です。
ここで、賢明な読者であれば、電磁界シミュレーションで計算するのであれば、わざわざ機械学習を使う意味があるのか?と考えるかもしれません。すでに配線条件が決まっている$Z_0$や$S$パラメータであれば、電磁界シミュレーションを直接行った方が短時間で高精度に計算できます。
しかし、ある条件を満たす$Z_0$や$S$パラメータを求めるとなるとシミュレーションは複数回行う必要があります。これらの電磁界シミュレーションは、1回あたりの計算時間は比較的短いので、10回程度であれば、大した時間でありません。しかし、図2 に示すように配線幅が10とおり、絶縁層厚が10とおり、配線長が10とおり、隣接配線間隔が10とおりあったと仮定すれば、すべての組み合わせは、10000とおり(=10×10×10×10)です。仮に1回のシミュレーション時間を1分とすれば、すべての組合わせを計算するには、167時間、つまり1週間の時間がかかります。
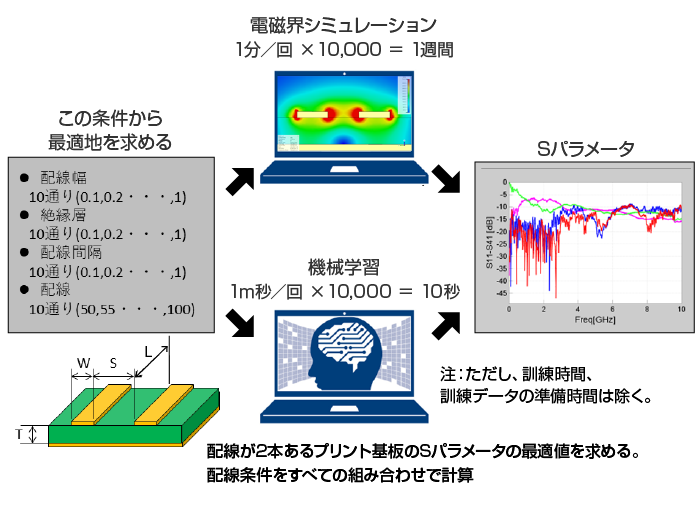
図2 電磁界シミュレーションと機械学習による最適化
これを機械学習に置き換えれば、1回の計算が1m秒に短縮できるので、10000回の計算を行っても僅か10秒ですべの計算が可能です。実際の最適化では、組み合わせが爆発する場合が多いので、すべての組合わせで計算は行いませんが、10000~100000とおりの計算を行うことは珍しくありません。
このように電磁界シミュレーションの代替としての利用が考えられます。ただし、訓練データの準備時間、機械の訓練時間は除きます。訓練データを100個、訓練時間を2時間としても、3時間40分あれば、機械学習により予測準備が整います。
回帰モデルと基板設計
プリント基板の設計データから信号波形の予測、放射電界の予測が可能です。電磁界シミュレータで行えること同じですが、機械学習は圧倒的に短時間で信号波形や放射電界を予測できる点が違います。
機械学習では、リアルタイムで信号波形や放射電界の予測が可能ですので、配線レイアウトを行いながら最適な設計が可能です。
この回帰モデルと遺伝的アルゴリズムを組み合わせれば、$S$パラメータ(クロストークや挿入損失)の目標値を示すだけで、自動的に配線レイアウトが導かれます。
● 分類問題
分類問題は、入力データを分類します。画像認識も画像をデータとして入力して、それに対応するラベル(注:画像に対応する名前。例えば、猫や犬など)を出力します。
図3 は遠方放射パターンから共振モードを出力する事例です。放射パターンと共振モードをラベルとした多数の訓練データを準備して、機械を訓練します。訓練が完了すれば、放射パターンに応じた共振モードを出力する分類器になります。放射パターンは電波暗室を使えば、実測データが準備でき、測定現場で直ちに共振モードの推定ができるので、放射源の特定が可能になります。
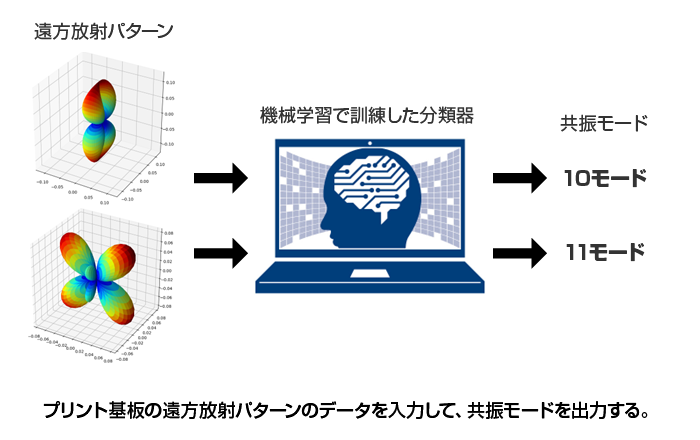
図3 放射パータンから共振モードを予測する分類問題
ほかの事例としては、図4 に示すプリント基板から放射されるノイズが規格値以下であれば合格、規定値を超えれば不合格の判断や基板設計の優劣を5段階評価することも可能です。この場合は、多数のプリント基板データとその基板から発生するノイズの測定結果、または、基板の良し悪しを判断できる見識者に5段階のラベルを付けてもらえば可能になります。しかし、数千や数万のCADデータに人間がラベル付けするのは、現実的ではありませんので、前述の電磁界シミュレーションを機械学習の回帰モデルに置き換えて、高速に放射ノイズを予測して自動でラベル付けしたほうがよいでしょう。
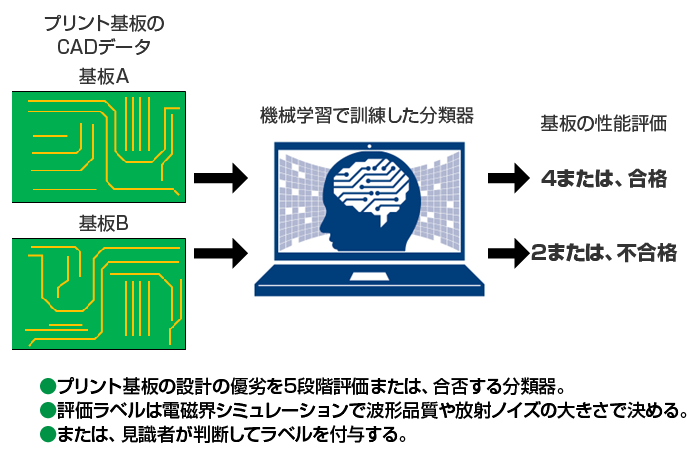
図4 プリント基板の設計を分類問題として評価
分類モデルと基板設計
信号波形や放射電界の限度値を決めて、それ以下であれば合格、限度値を超えた場合は不合格と決めれば、配線レイアウト情報を入力するだけで、基板設計に対する合否は判定が可能です。回帰モデルと同様に、配線レイアウトを行いながらリアルタイムでの判定が可能です。
■ 教師なし学習
教師なし学習とは、その名前のとおり、ラベルとなるデータがありません。これは、入力データさえ準備すれば、機械が勝手にデータを分類します。機械が勝手に分類するといっても、一定のルールに則り分類します。
図5 に示す に示すK-means と呼ばれるクラスタリングでは、データとクラスタ重心間距離を計算し、最も近い重心を持つクラスタに分類されます。最初の重心はランダムに決めて、その重心に属するデータの平均値をとり、それを新しい重心として、重心が動かなくなるまで計算を行います。また、K-meansでは、クラスタ数は人間が指定します。また、分類されたクラスタに意味をもたせるのも、人間側の作業になりますので、必ずしも、意味のある分類ができるとは限りません。
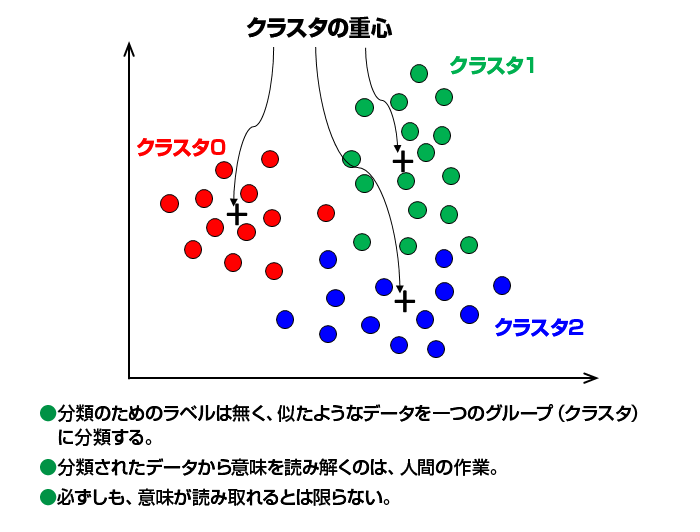
図5 教師なし学習(クラスタリング)
クラスタリングと基板設計
クラスタリングは似たようなデータどうしをグループ化するものです。
プリント基板の近傍磁界の分類に利用でき、処理は数分で完了します。近傍磁界の測定結果は周波数ごとにあり、しかも2次元のデータなので、データを観察するのも一苦労しますが、図6 に示すように、似たような分布の磁界データごとにグループ化するとデータの見通しが良くなります。教師あり学習の分類モデルを作る時の前処理として利用することが可能です。

図6 近傍磁界のクラスリング事例
クラスタリングはデータを分類するのと同時に分類器も作られます。この分類器はクラスタの番号しか出力されないので、クラスタの番号に意味のあるラベルを対応させることができれば、教師あり学習の分類器として利用できます。
図4 に示したプリント基板設計の優劣を判断する分類器も、クラスリングで5つに分け、クラスタ番号と基板設計の評価値(1~5)を関連付けることにより教師ありの分類器として利用できます。ただし、クラスタリング自体は、あくまでも似たようなデータを同じクラスタにするだけですので、思ったように分類されない事もありますので、注意が必要です。
● 強化学習
強化学習は、教師あり学習のような正解ラベルが不要で、機械が試行錯誤しながら、正解を導く学習方法になります。自動運転や将棋ゲームなどに利用されています。教師データが不要で、ルールと報酬と、ペナルティの条件を与えれば、報酬が増えるように機械が自動的に学習します。
強化学習は、配線設計への利用が考えられます。これは、配線が交叉した場合や配線間隔が適切でない場合、ペナルティを与え、配線長は短い方が報酬が高くなるように設定すれば、配線設計が可能になります。また、先に述べた電磁界シミュレータの回帰モデルが背後で動作して、$S$パラメータや放射電界をリアルタイムで計算しながら、自動配線することも可能になります。
■ 機械学習に使われるアルゴリズム
機械学習の代表的なアルゴリズムを表1 に示します。
| 回帰問題 | 分類問題 | クラスタリング |
|---|---|---|
| ガウス過程回帰 | ロジスティック回帰 | K-means |
| ランダムフォレスト | ランダムフォレスト | DB Scan |
| 勾配ブースティング | 勾配ブースティング | ガウス混合モデル(GMM) |
| サポートベクターマシーン | サポートベクターマシーン | |
| ニューラル・ネットワーク | ニューラル・ネットワーク |
表1 機械学習に使われるアルゴリズム
ここで述べるアルゴリズム以外にも多くのアルゴリズムがあります。また、ニューラル・ネットワークは、さらに細かく分類できます。一般的に分類問題に使えるアルゴリズムは回帰問題にも利用できます。前述のとおりに分類を連続的に無限に分割したものが回帰問題になるためです。
ニューラル・ネットワーク以外の機械学習は、訓練データの規模によりますが、訓練時間が数十秒から数分程度で完了します。特にランダムフォレストや勾配ブースティングは、訓練データを多く準備できれば、短い時間で分類器や回帰モデルが作れます。
ニューラル・ネットワークは非常に広範囲で利用できるのですが、ネットワーク構造も自由に定義できるので、逆に自由度が大きすぎて、初めて使うには、やや敷居が高いです。また、訓練時間もほかの機械学習に比較して長い時間がかかりますし、ネットワークを調整しながら機械を訓練する必要があるため、初学者にはお勧めしません。
次回以降では、実際に機械学習を使った分類器や回帰モデルの作り方を解説します。